From Borg to Kubernetes
Overview
Teaching: 0 min
Exercises: 0 minQuestions
What does it mean to orchestrate?
What is the difference between traditional job management system and container management system?
Objectives
Understand the rise in abstraction levels as computing task moves from executing a job to running a container
Understand the relationship between container engine and container orchestration system
Be familiar with common open-source orchestration systems
1. What does orchestrate mean
- Dictionary definition: to arrange or combine so as to achieve a desired or maximum effect
- Recall Kubernetes documentation: We tell Kubernetes what the desired state of our system is like, and Kubernetes will work to maintain that
- Before containerization/virtualization, we have cluster of computers running jobs.
- Jobs = applications running on single or multiple computing nodes
- Applications’ dependencies are tied in to the supporting operating system on these nodes.
- Cluster management system only need to manage applications.
- Container is more than an application.
- A lightweight virtualization of an operating system and its components that help an application to run, including external libraries.
- A running container does not depending on a host computer’s libraries.
- Is the management process the same as a cluster management system?
2. Borg, a cluster management system
- Google’s Cluster Management System
- First developed in 2003.
- Abhishek Verma, Luis Pedrosa, Madhukar Korupolu, David Oppenheimer, Eric Tune, and John Wilkes. “Large-scale cluster management at Google with Borg.” In Proceedings of the Tenth European Conference on Computer Systems, p. 18. ACM, 2015.
- Manages hundreds of thousands of jobs, from many thousands of different applications, across clusters up to tens of thousands machines.
3. Why Borg and Kubernetes
- Borg is the predecessor of Kubernetes. Understand Borg helps understand the design decision in creating Kubernetes.
- Kubernetes is perhaps the most popular open-source container orchestration system today, for both academic and industry.
- Other container orchestration systems are either
- Deprecating (Docker Swarm)
- Integrates container management as part of the existing framework rather than developing a new management system (UC Berkeley’s Mesos and Twitter’s Aurora)
- We will briefly discuss them at the end of this episode.
4. Benefits of Borg
- Hides the details of resource management and failure handling so its users can focus on application development.
- Operates with very high reliability and availability, and supports applications that have similar requirements.
- Runs workloads across tens of thousands of machines efficiently.
- Is not the first system that can do these, but is one of the very few that can do it at such scale.
5. User’s perspective
- Work is submitted to Borg as jobs, which can have one or more tasks (binary).
- Each job runs in one Borg cell, consisting of multiple machines that are managed as a single unit.
- Job types:
- Long running services that should never goes down and have short-lived latency-sensitive requests: Gmail, Google Docs, Web Search …
- Batch jobs that take a few seconds to a few days to complete.
- Borg cells allow for not just applications, but applications frameworks
- One master job and one or more worker jobs.
- The framework can execute parallel applications itself.
- Examples of frameworks running on top of Borg:
- MapReduce
- FlumeJava: Data-Parallel Pipelines
- Millwheel: Fault-tolerant Stream Processing at Internet Scale
- Pregel: Large-scale graph processing
6. Clusters and cells in Borg
- Machines in cells belong to a single cluster, defined by the high-performance datacenter-scale network fabric connecting them.
- How is this different that the traditional cluster model?
- A Borg’s alloc defines a reserved set of resources on a machine in which one or more tasks can be run.
7. Jobs and tasks
- A job consists of multiple tasks
- Jobs have constraints that allow them to map to machines with satisfactory attributes
- Tasks:
- Each task maps to a set of Linux processes.
- Authors’ notes: Borg was not designed for virtualization (2003).
- Also has resource requirements (CPU cores, RAM, disk space, port available …)
- All Borgs’ programs are statically linked.
- What does this mean?
- Why?
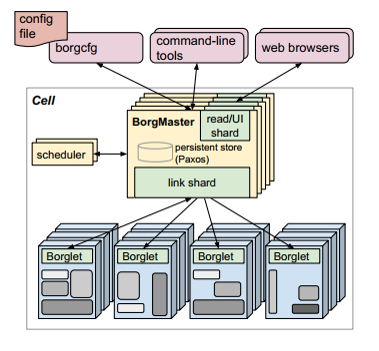
8. Borg’s architecture
- Borg Master
- Borglet
- Sound familiar? (Kuber Master and Kubelet)
9. Borg Master
- Consists of two process:
- The main Borgmaster process
- The scheduler
- Borgmaster:
- Replicated five times
- Contains in-memory copy of most of the state of the cell
- Handles client RPCs that either mutate state (create jobs) or provide read-only access to data.
- Manages state machines for all the objects in the system (machines, tasks, allocs …)
- Scheduler:
- Perform feasibility check to map tasks’ constraints to available resources.
- Picks one of the feasible machines to run the tasks.
10. Borglet
- Local Borg agent that is present on every machine in a cell.
- Starts and stops tasks, restarts if failed.
- Manages local resources through OS kernel manipulations
- Reports state of the machine to the Borgmaster.
11. Scalability of Borg Master
- Reported in the 2015 paper:
- Unsure of the ultimate scalability limit (flex anyone?)
- A single master can
- manage many thousands machines in a cell
- several cells have arrival rates of more than 10,000 tasks per minute.
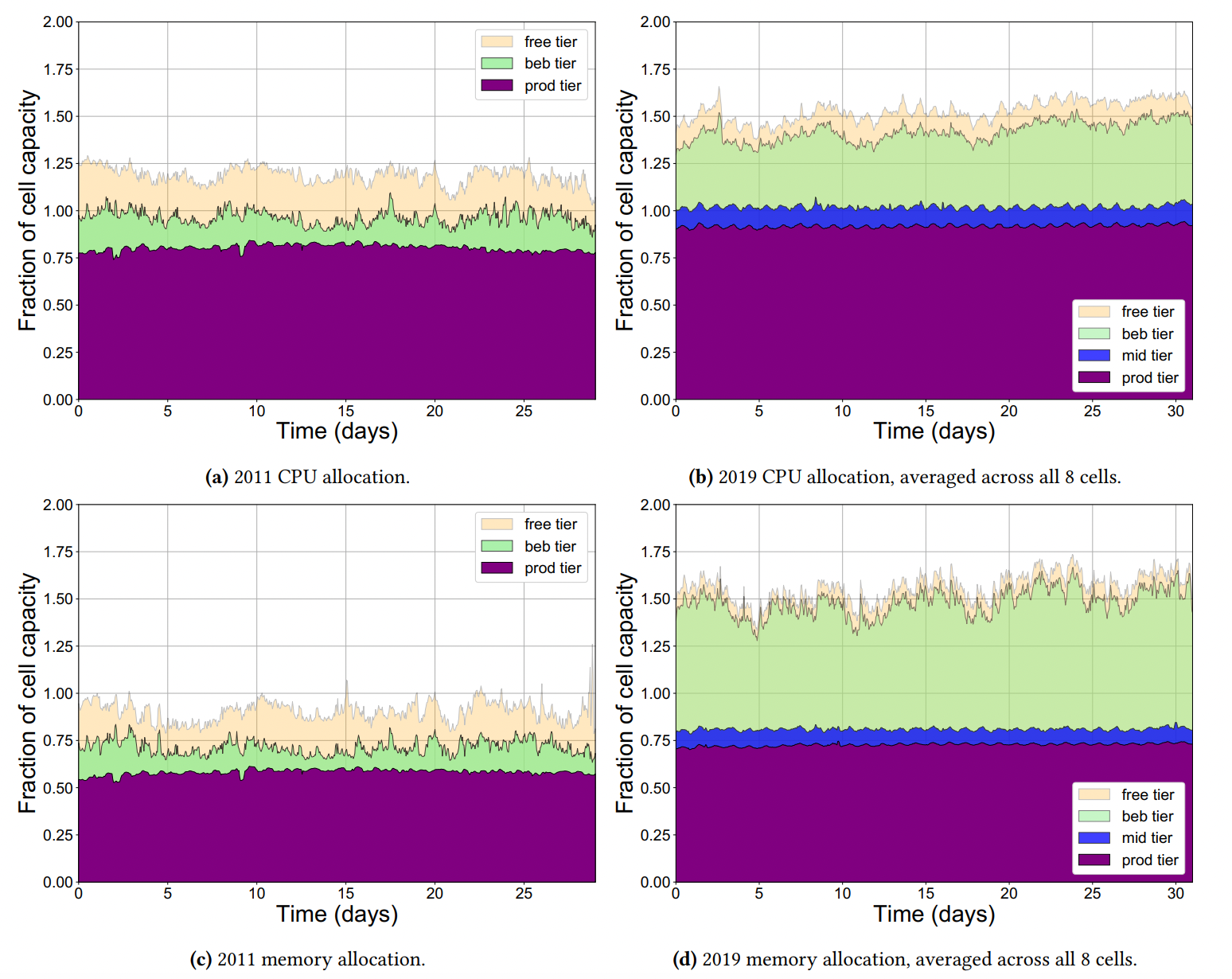
- 2020 Borg analysis report:
- (Muhamad Tirmazi, Adam Barker, Nan Deng, Md E. Haque, Zhijing Gene Qin, Steven Hand, Mor Harchol-Balter, and John Wilkes. “Borg: the next generation.” In Proceedings of the fifteenth European conference on computer systems)[https://dl.acm.org/doi/pdf/10.1145/3342195.3387517]
- 2011 log data: 1 cell, 12000 machines (40 GB compressed)
- 2020 log data: 8 cells, 96000 machines (350 GB compressed)
- The below graph show fraction of CPU and memory allocation of each category of priority queue **relative to cell’s capacity”.
- What is special about this?
- Keyword: overcommit since 2011.
12. Isolation
- Sharing machines between tasks help improving utilization
- Security Isolation:
- Need good security isolation mechanism among multiple tasks on the same machine.
chrootto jail processes. SSH-connection is used for communication.- VMs are utilized to sandbox external software (Google App Engine and Google Compute Engine). A VM is run as a single task.
- Performance isolation
- Application’s class: latency-sensitive and batch (batch can be allowed to starved)
- Resources:
- Compressible: rate-based and can be reclaimed without killing the tasks (CPU cycles, I/O bandwidth)
- Incompressible: cannot be reclaimed (memory, disk space)
13. Kubernetes: where does it come from
- Developed from lessons learned via Borg
- Become available with the initial release of Docker in March 2013
14. Kubernetes: applications versus services
- A service is a process that:
- is designed to do a small number of things (often just one).
- has no user interface and is invoked solely via some kind of API.
- An application is a process that:
- has a user interface (even if it’s just a command line) and
- often performs lots of different tasks. It can also expose an API,
- It is common for applications to call several service behind the scenes
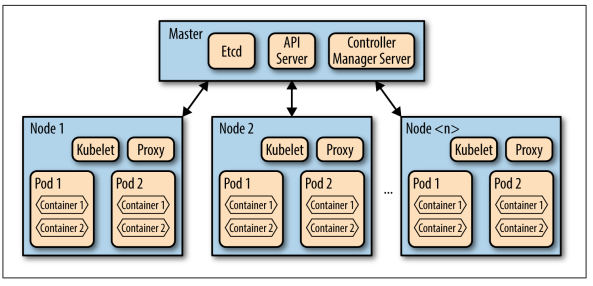
15. Kubernetes: what does it have?
- Kubelet: a special background process responsible for create, destroy, and monitor containers on a host.
- Proxy: a simple network proxy used to separate IP address of the container from the service it provides.
- cAdvisor: collects, aggregates, processes, and exports information about running containers.
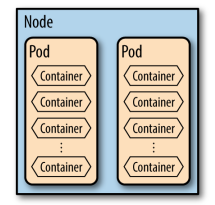
- Pods
- A collection of containers and volumes that are bundled and scheduled together because they share a common resource (same file system or IP address).
- Docker: Each container gets its own IP
- Kubernetes: Containers of a pod share the same address.
- A pod emulates a logical host (like a VM) to the containers.
- Important:
- Kubernetes schedules and orchestrates things at the pod level, not at the container level.
- Containers running in the same pod have to be managed together (shared fate).
- Management transparency: You don’t have to micromanage processes within a pod.
16. What Kubernetes learned from Borg
- Rejection of the
jobconcept and organize around the concept ofpods.
labelsare used to described theobjects(jobs,services, …) and their desired states.- IP addresses are mapped to
podsandservicesand not physical computers.- Optimizations for high-demand jobs.
- The perception of Kubernetes’ kernel as an operation system kernel for a distributed system.
17. Borg, Oemga, and Kubernetes
- Burns, Brendan, Brian Grant, David Oppenheimer, Eric Brewer, and John Wilkes. “Borg, Omega, and Kubernetes.” Queue 14, no. 1 (2016): 10.
- Borg:
- Isolation through the root file system (chroot, cgroups).
- A modern container is more than just an isolation mechanism: It is also an image, files that make up the applications that runs inside the container.
- Application-oriented infrastructure
- Containerization transform the data center from being machine-oriented to being application-oriented.
- Containers encapsulate the application environment, abstracting away many details of machines and OS from the application developer and the deployment infrastructure.
- Managing containers means managing applications rather than machines.
- Application environment
- Decoupling of image and OS.
- Hermetic image:
- What is hermetic?
- Encapsulation almost all dependencies except Linux kernel system-call interface.
- Containers as the unit of management
- Relieves application developers and operations teams from worrying about specific details of machines and OS.
- Provides the infrastructure team flexibility to roll out new hardware and upgrade the OS with minimal impact on running applications and their developers.
- Ties telemetry collected by the management system to applications rather than to machines.
18. Orchestration is only the beginning …
- Many new systems have been built around Borg to improve its container-management services
- Naming and service discovery
- Master election
- Application-aware load balancing
- Horizontal and vertical scaling
- …
- Kubernetes attempts to avoid escalating complexity through a consistent approach in its API.
19. Other container management system
- Recalling Hadoop YARN (Yet Another Resource Negotiator)
- Second generation scheduler for Hadoop (Open-source implementation of Google File System)
- Deployment of software frameworks as jobs
- Apache Mesos is more similar to YARN and Borg than Kubernetes
- Cluster management system
- Containers are executed as jobs.
- Twitter’s Aurora is a scheduler running on top of Mesos.
- Configurations are more complex, but is still a cluster management system.
Key Points
Container orchestration systems grow from traditional