Schedulers for cluster of computers
Overview
Teaching: 0 min
Exercises: 0 minQuestions
What does it mean to schedule jobs on a supercomputer?
Objectives
1. Introduction
- The term
schedulingimpacts several levels of the system, from application/task scheduling which deals with scheduling of threads to meta-scheduling where jobs are scheduled across multiple supercomputers.- Here, we focus on
job-scheduling, scheduling of jobs on a supercomputer, the enabling software infrastructure and underlying algorithms.- This is an optimization problem in packing with space (processor) and time constraints
- Dynamic environment
- Tradeoffs in turnaround, utilization, and fairness
2. Introduction: Job scheduling
- Simplest way to schedule in a parallel system is using a queue
- Each job is submitted to a queue and each job upon appropriate resource match executes to completion while other jobs wait.
- Since each application utilizes only a subset of systems processors, the processors not in the subset could potentially remain idle during execution. Reduction of unused processors and maximization of system utilization is the focus of much of scheduling research.
- Space Sharing: A natural extension of the queue where the system allows for another job in the queue to execute on the idle processors if enough are available.
- Time Sharing: Another model where a processor’s time is shared among threads of different parallel programs. In such approaches each processor executes a thread for some time, pauses it and then begins executing a new thread. Eg. Gang Scheduling
- Since context switching in Time Sharing involves overhead,complex job resource requirements and memory management, most supercomputing installations prefer space sharing scheduling systems.
3. CPU scheduling
- Scheduling of CPUs is fundamental to Operating System design
- Process execution consists of a cycle of CPU execution and I/O wait. The process execution begins with a CPU burst followed by an I/O burst etc.
- OS selects one of the processes from the short term scheduler / CPU scheduler.
- The scheduler selects from among the process in memory that are ready to execute and allocates the CPU to one of them.
- Scheduling happens under one of 4 conditions:
- When process switches from running state to the waiting state (Non Preemptive)
- When a process switches from the running state to the ready state (Preemptive)
- When a process switches from the waiting state to the ready state (Preemptive)
- When a process terminates (Non Preemptive)
4. CPU scheduling
- Scheduling Criteria:
- MAX CPU Utilization needs to keep the CPU as busy as possible.
- MAX Throughput Number of processes completed per time unit
- MIN Turnaround Time the interval from the time of submission of a process to the time of completion
- MIN Waiting Time Sum of the periods spent by the process waiting in the ready queue
- MIN Response Time The measure of time from the submission of a request until the first response is produced
5. Workload management systems
- Supercomputing Centers often support several hundreds of users running thousands of jobs across a shared supercomputing resources consisting of large number of compute nodes and storage centers.
- It can be extremely difficult for an administrator of such a resource to manually manage users, resource allocations and ensure optimal utilization of the large supercomputing resources.
- Workload management systems (WMS) help address this problem by providing users with simple resource access and for the administrator of the supercomputing resource, a set of powerful tools and utilities for resource management, monitoring, scheduling, accounting, and policy enforcement.
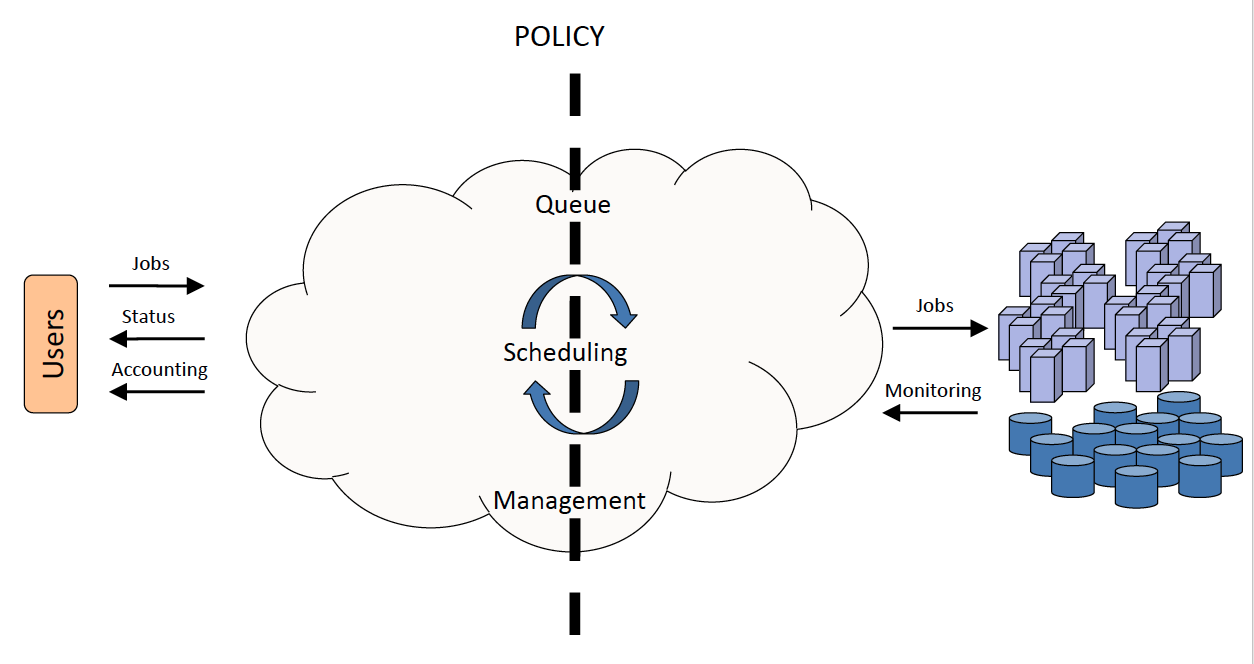
6. Workload management systems: main activities
- Queuing
- Scheduling
- Monitoring
- Resource Management
- Accounting
7. Workload management systems: a layer between users and computing resources
- Users submit jobs, specifying the work to be performed, to a queue
- Jobs wait in queue until they are scheduled to start on the cluster.
- Scheduling is governed by stipulated policies and algorithms that implement the policy. (Policies usually ensure fair sharing of resources and attempt to optimize overall system utilization.)
- Resource management mechanisms handle launching of jobs and subsequent cleanup.
- The workload management system is simultaneously monitoring the status of various system resources and accounting resource utilization.
8. Workload management systems: queueing
- The most visible part of the WMS process where the system collects the jobs to be executed.
- Submission of jobs is usually performed in a container called a
batch job(usually specified in the form of a file).- The batch job consists of two primary parts :
- A set of resource directives (number of CPUs, amount of memory etc.)
- A description of the task(s) to be executed (executable, arguments etc.)
- Upon submission the batch job is held in a queue until a matching resource is found. Queue wait time for submitted jobs could vary depending on the demand for the resource among users.
- Production or real world supercomputing resources often have multiple queues, each of which can be preconfigured to run certain kinds of jobs. ExampleTezpurcluster has a debug queue and workq
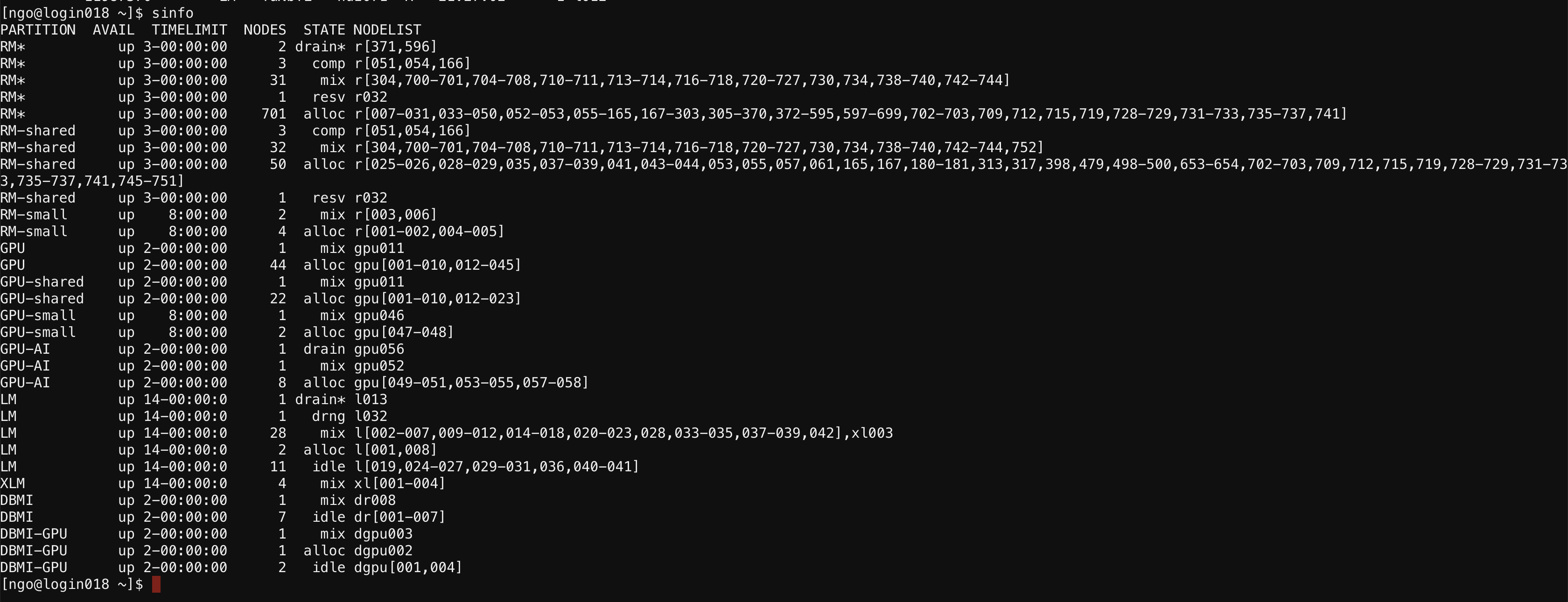
9. Workload management systems: scheduling
- Scheduling selects the best job to run based on the current resource availability and scheduling policy.
- Scheduling can be generally broken into two primary activities :
- Policy enforcement : To enforce resource utilization based on policies set by supercomputing sites (controls job priority and schedulability).
- Resource Optimization : Packs jobs efficiently, and exploit underused resources to boost overall resource utilization.
- Balancing policy enforcement with resource optimization in order to pick the best job to run is the difficult part of scheduling
- Common scheduling algorithms include First In First Out, Backfill, Fairshare.
10. Workload management systems: monitoring
- Resource monitoring by WMS, provides administrators, users and scheduling systems with status information of jobs and resources. Monitoring is often performed for 3 critical states:
- For
idle nodes, to verify their working order and readiness to run another job.- For
busy nodes, to monitor memory, CPU, network, I/O and utilization of system resources to ensure proper distribution of workload and effective utilization of nodes.- For
completed jobs, to ensure that no processes remain from the completed job and that the node is still in working order before a new job is started on it.
11. Workload management systems: resource management
- Resource Management area is responsible for starting, stopping, and cleaning up after jobs.
- A batch system resource management is setup in such a way so as to run the jobs using the identity of a user in such a way that the user need not be present at that time.
- Jobs are started only on the nodes that are functioning properly.
- Resource management also includes removing or adding of resources to the available pool of systems
- Clusters are dynamic resources, systems go down, or additional resources are added.
- Registration of new nodes and the marking of nodes as unavailable are additional aspects of resource management
12. Workload management systems: accounting and reporting
- Workload accounting can be defined as the process of collecting resource usage data for the batch jobs that run on the resource. (example % CPU utilization, memory utilization etc.)
- Data obtained from accounting is often used to :
- Produce weekly/monthly per user usage reports
- Tuning of scheduling policy
- Calculating future resource allocations
- Anticipating future computer component requirements
- Determining areas for improvement within the system.
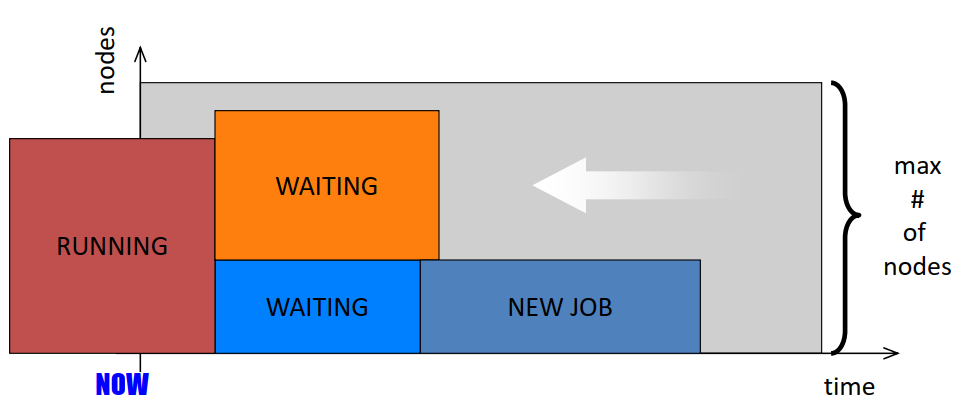
13. Scheduling algorithm: FCFS/FIFO
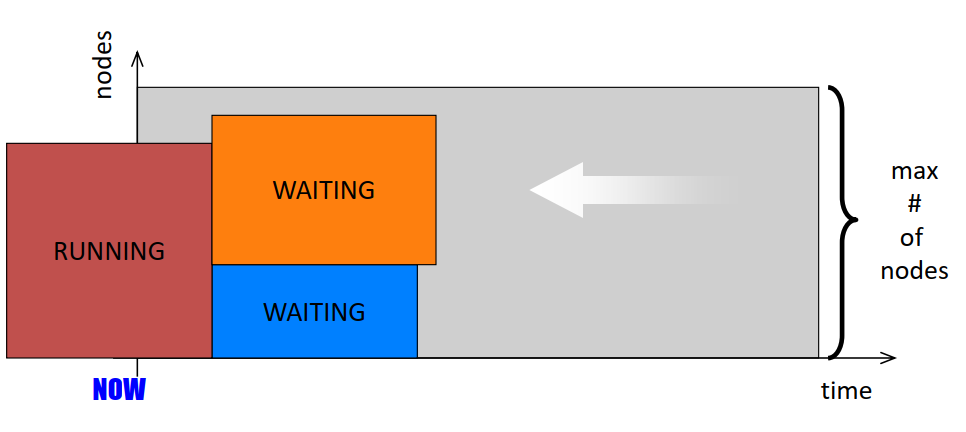
- Definitions
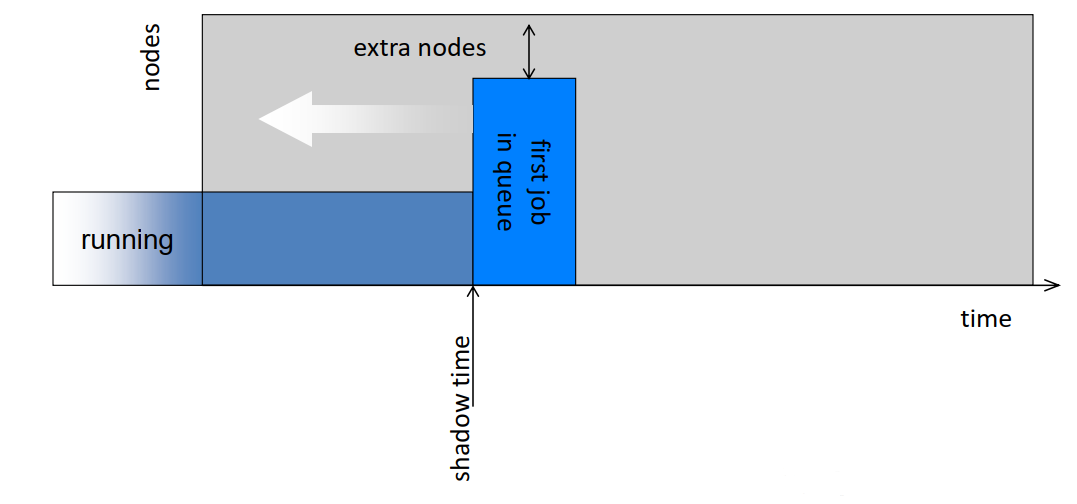
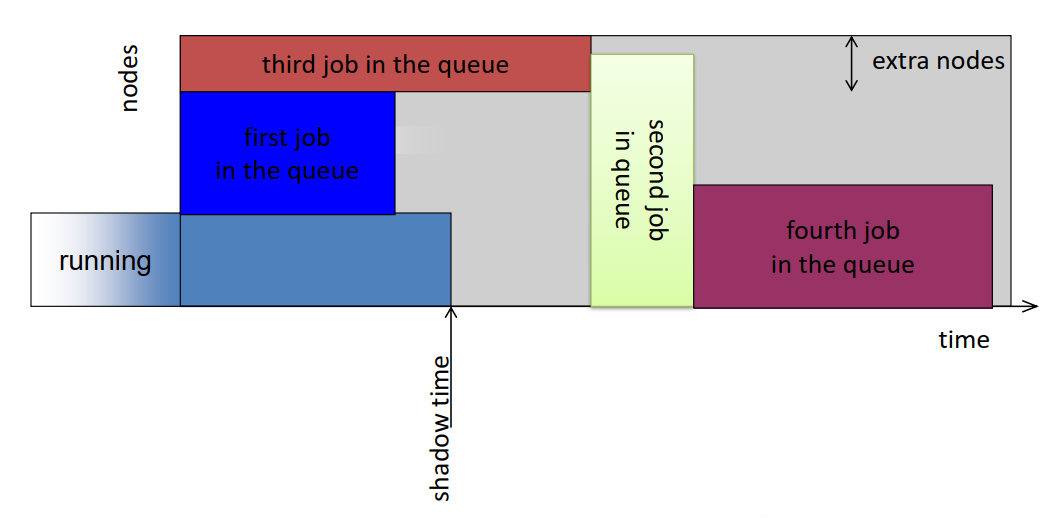
- Shadow time: time at which the first job in the queue starts execution
- Extra nodes: number of nodes idle when the first job in the queue starts execution
- Simplest scheduling option: FCFS
- First Come First Serve
- Problem:
- Fragmentation:
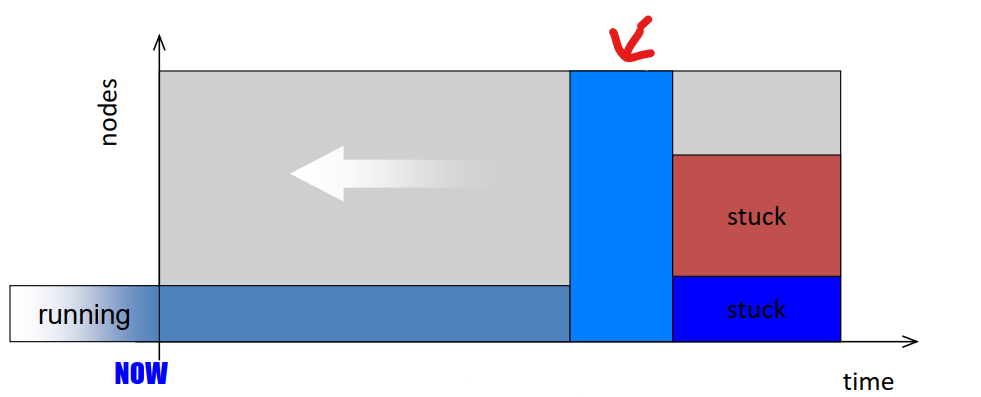
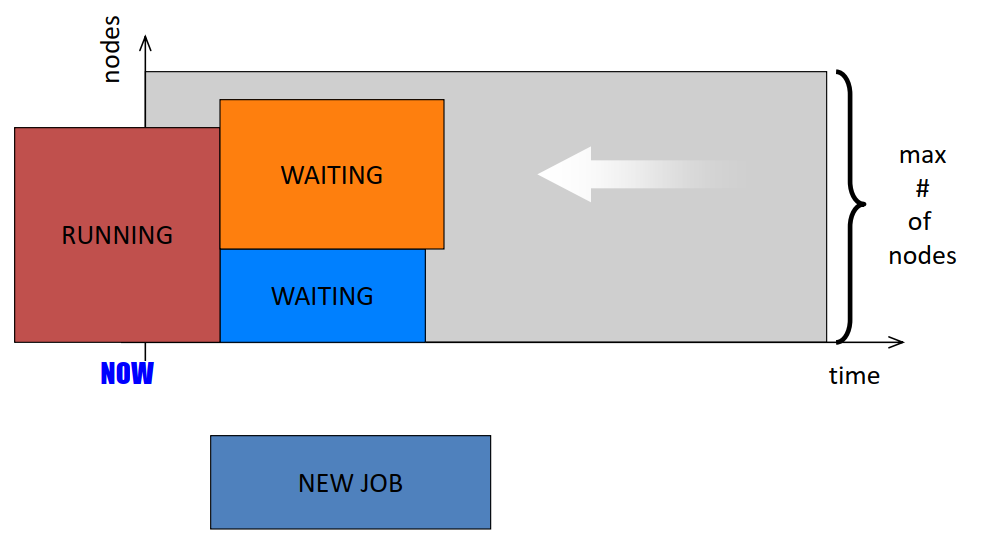
14. Scheduling algorithm: FCFS with Backfilling
- Which job(s) should be picked for promotion through the queue?
- Many heuristics are possible
- Two have been studied in detail
- EASY
- Conservative Back Filling (CBF)
- In practice EASY (or variants of it) is used, while CBF is not
- Extensible Argonne Scheduling System
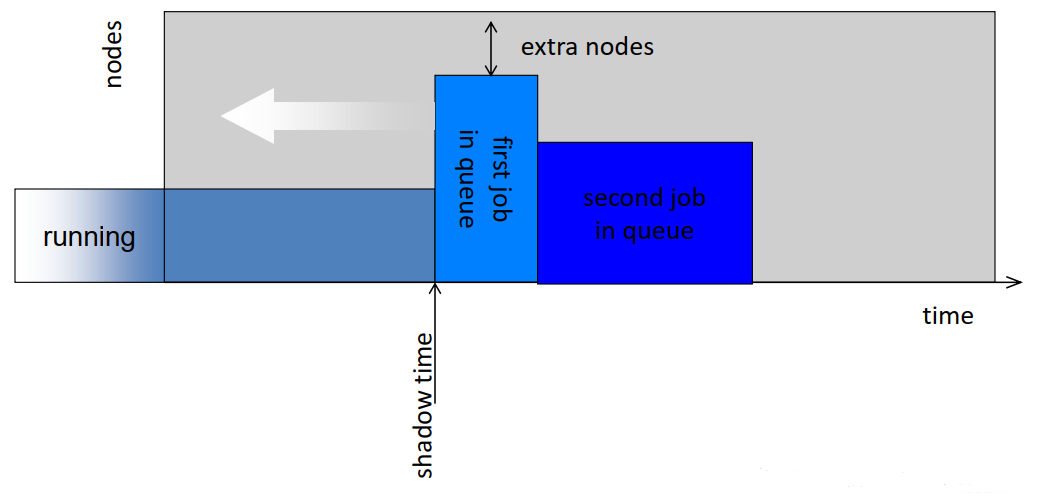
- Maintain only one “reservation”, for the first job in the queue
- Go through the queue in order starting with the 2nd job
- Backfill a job if
- it will terminate by the shadow time, or
- it needs less than the extra nodes
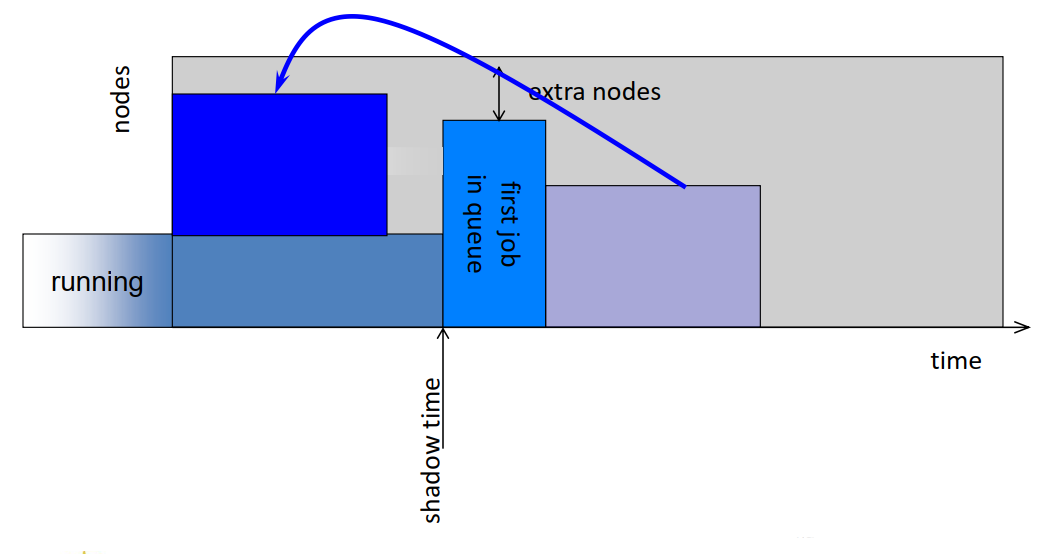
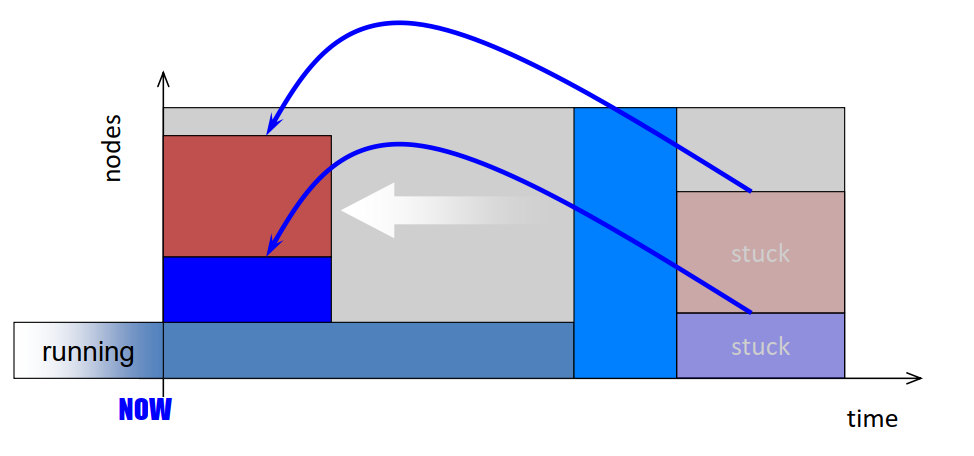
- Problem:
- The first job in the queue will never be delayed by backfilled jobs
- BUT, other jobs may be delayed infinitely!
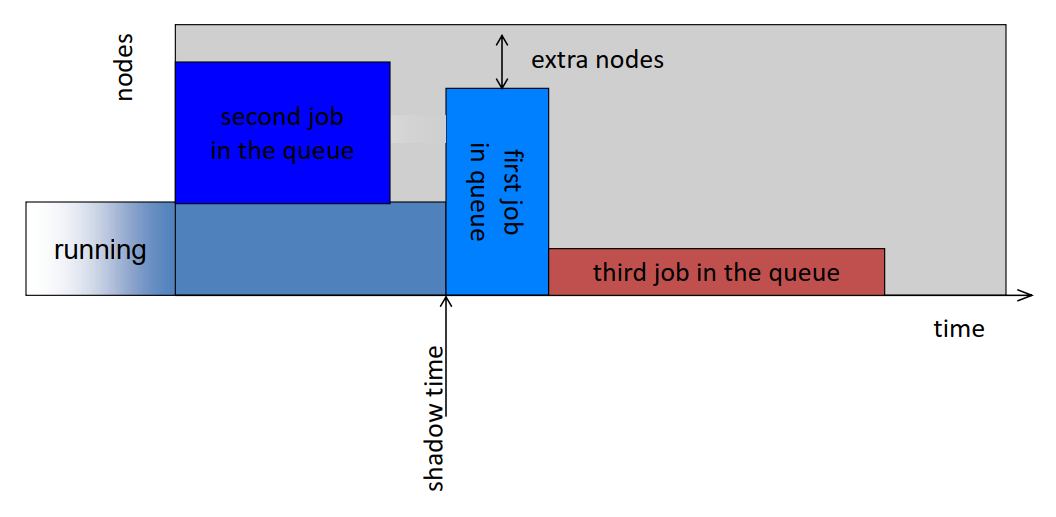
- Unbounded Delay
- The first job in the queue will never be delayed by backfilled jobs
- BUT, other jobs may be delayed infinitely!
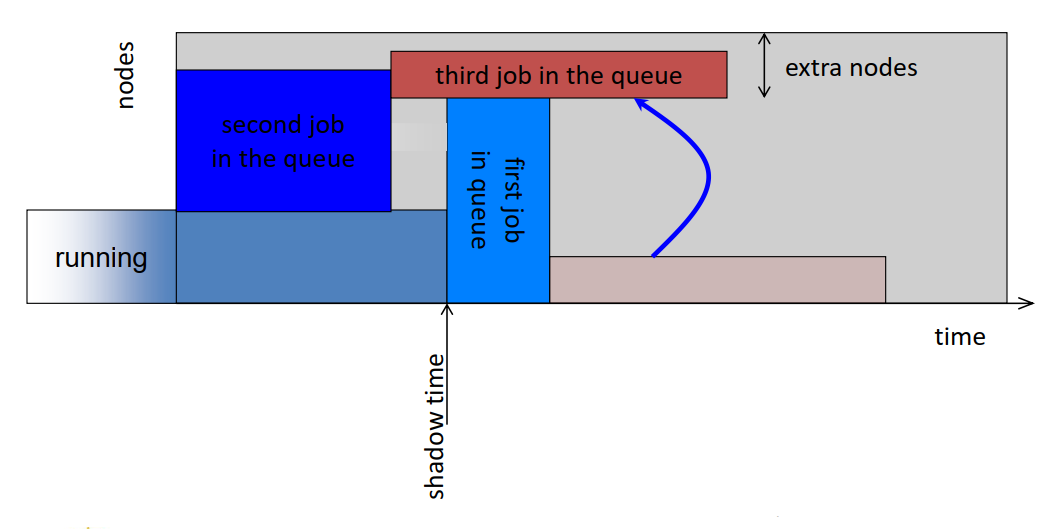
- No starvation
- Delay of first job is bounded by runtime of current jobs
- When the first job runs, the second job becomes the first job in the queue
- Once it is the first job, it cannot be delayed further
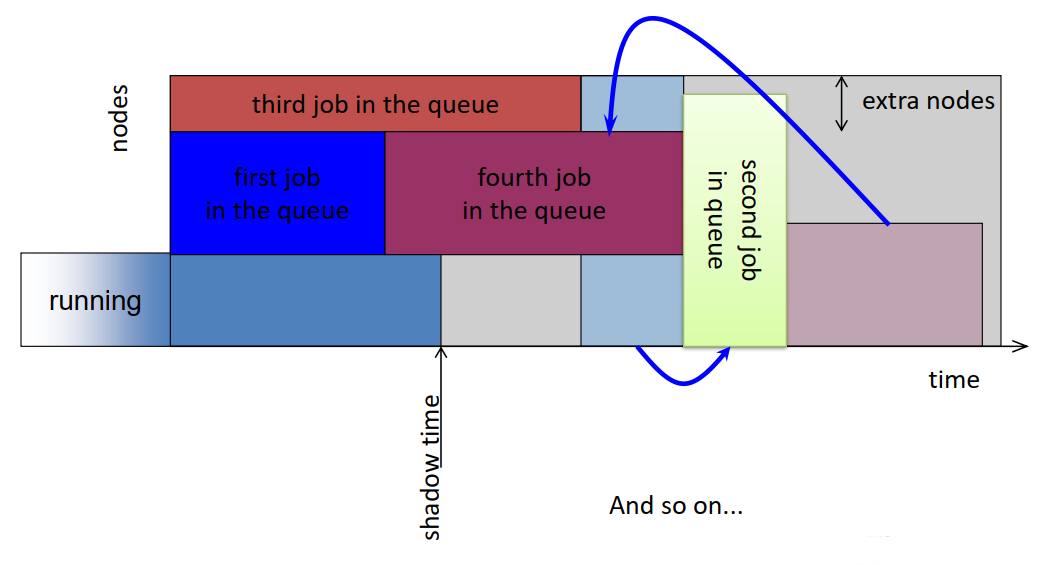
- EASY favors small long jobs
- EASY harms large short jobs
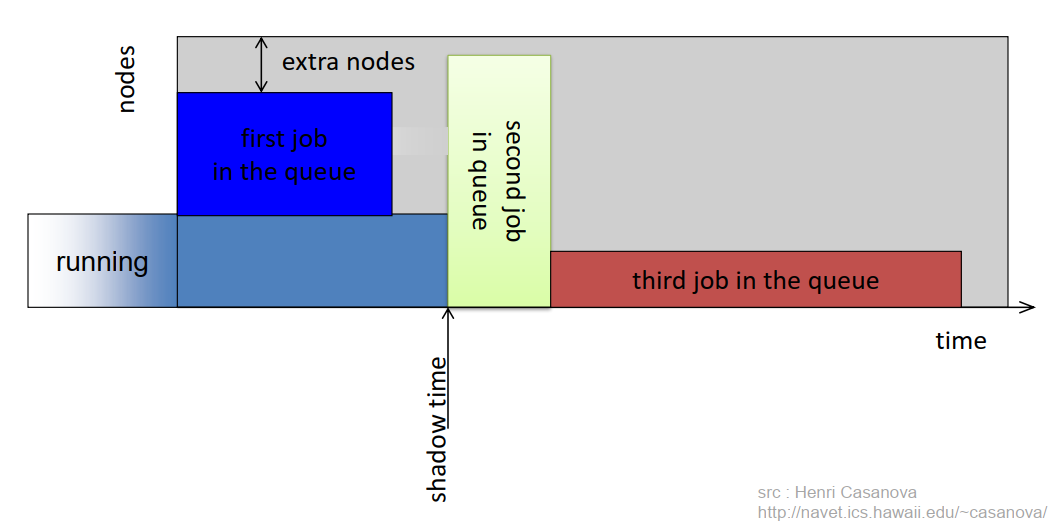
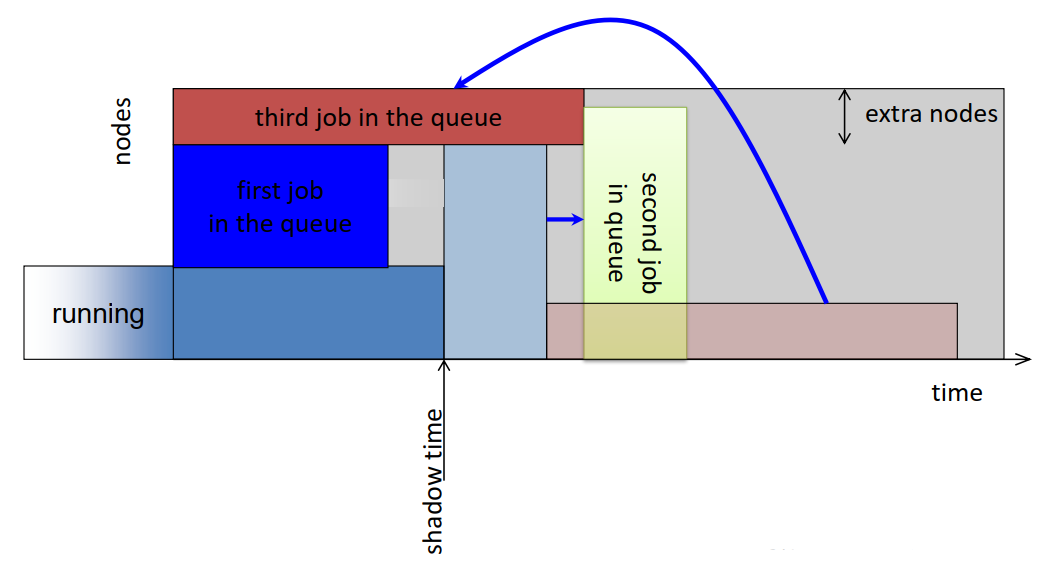
15. Conservative Backfilling
- EVERY job has a “reservation”
- A job may be backfilled only if it does not delay any other job ahead of it in the queue.
- Fixes the unbounded delay problem that EASY has
- More complicated to implement: The algorithm must find holes in the schedule
16. How good is the schedule?
- All of this is great, but how do we know what a
goodschedule is?
- FCFS, EASY, CFB, Random?
- What we need are metrics to quantify how good a schedule is
- It has to be an aggregate metric over all jobs
- Metric #1:
Turn-around time
- Also called flow
- Wait time + Run time
- But:
- Job #1 needs 1h of compute time and waits 1s
- Job #2 needs 1s of compute time and waits 1h
- Clearly Job #1 is really happy, and Job #2 is not happy at all
- Metric #2: wait time
- But
- Job #1 asks for 1 node and waits 1 h
- Job #2 asks for 512 nodes and waits 1h
- Again, Job #1 is unhappy while Job #2 is probably sort of happy
17. SLURM Scheduler
- Work funded by Department of Energy at Lawrence Livermore National Laboratory.
- SLURM: Simple Linux Utility for Resource Management.
- SLURM characteristics:
- Simple
- Open source
- Portable (written in C, requires no kernel modification)
- Fault-tolerant
- Secure
- System administrator friendly
- Scalable (16K nodes, 128K processors)
18. SLURM Scheduler: entities
- Nodes: Individual computers
- Partitions: Job queues
- Jobs: Resource allocations
- Job steps: Set of (typically parallel) tasks

19. SLURM Scheduler: job states
- Jobs:
- Resource allocation: specific processors and memory or entire nodes allocated to a user for some time period.
- Can be interactive (executed in real-time) or batch (script queued for later execution).
- Many constraints available for user request
- Identified by ID number
- Job steps:
- A set of tasks launched at the same time and sharing a common communication mechanism (e.g. switch windows configured for the tasks).
- Allocated resources within the job’s allocation
- Multiple job steps can executed concurrently or sequentially on unique or overlapping resources
- Identified by ID number:
jobid.stepid

20. SLURM Scheduler: control daemon and compute node daemon
- Control daemon:
slurmctld
- Orchestrates SLURM activities across the cluster
- Primary components
- Node Manager: Monitors node state
- Partition Manager: Groups nodes into partitions with various configuration parameters and allocates nodes to jobs
- Job Manager: Accepts user job requests and places pending jobs into priority-ordered queue. Uses the partition manager to allocate resources to the jobs and then launch them.
- Compute node daemon:
slurmd
- Monitors state of a single node
- Manages user jobs and job steps within that node
- Very light-weight
- Supports hierarchical communications with configurable fanout (new in version 1.1)

Key Points