Distributed File Systems
Overview
Teaching: 0 min
Exercises: 0 minQuestions
How to arrange read/write accesses with processes running on computers that are part of a computing cluster?
Objectives
0. Hands-on: What does it take to run MPI on a distributed computing system?
- Log into CloudLab
- Go to
Experiments/My Experiments
- Go to the
DistributedFSexperiment underExperiments in my Projects.
- Under the
List Viewtab,SSH commandcolumn, use the provided SSH command to login tocompute-1.
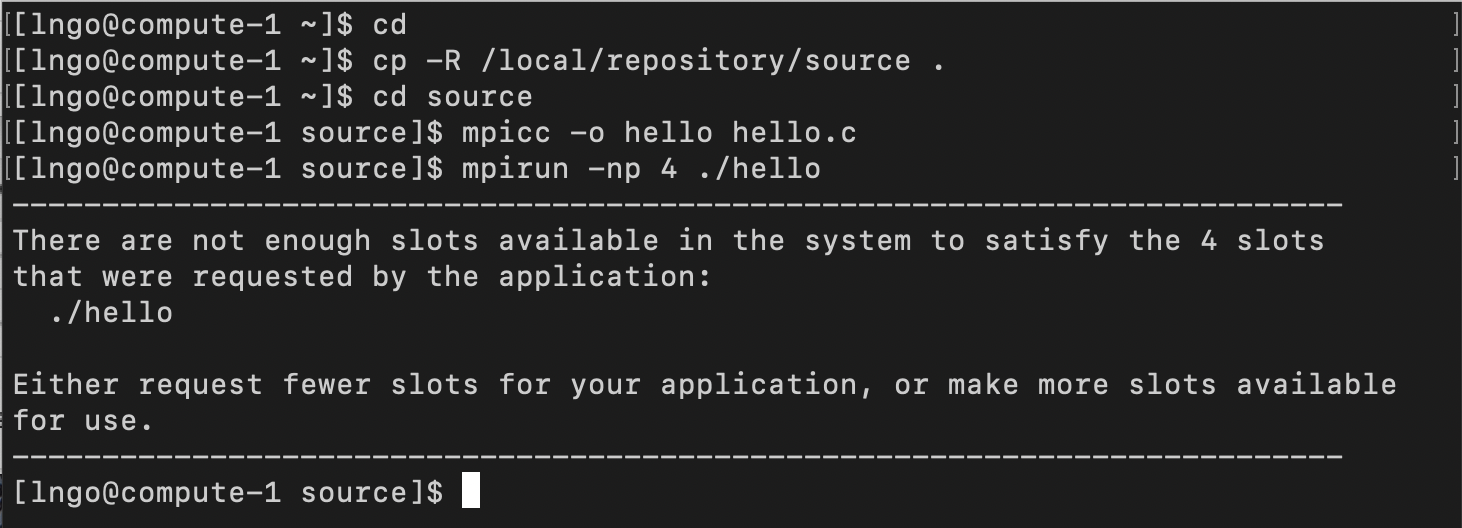
- Run the following bash commands from your home directory:
$ cd $ cp -R /local/repository/source . $ cd source $ mpicc -o hello hello.c $ mpirun -np 4 ./hello
- What does it take to run on multiple cores?
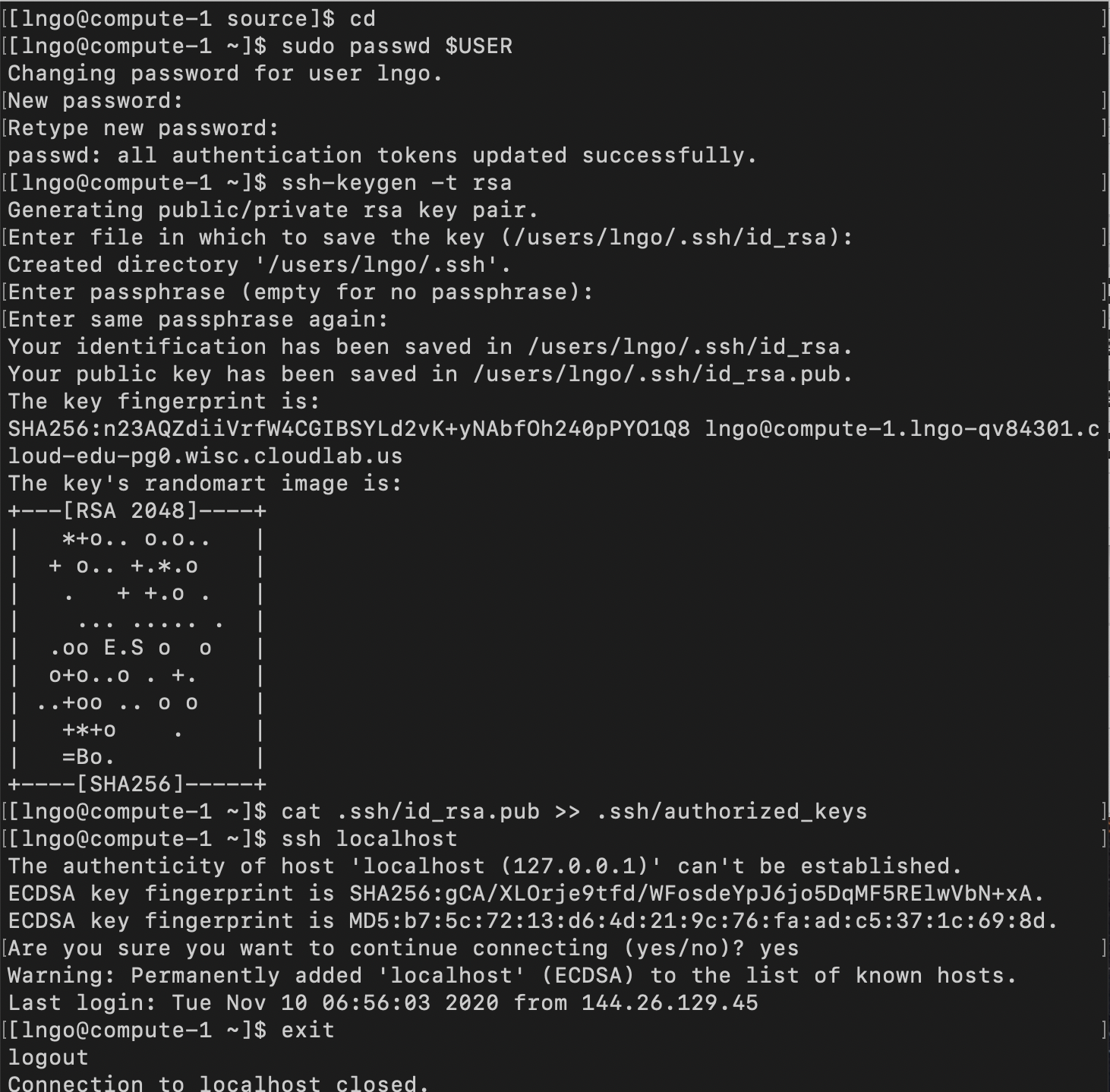
- MPI runs on SSH: needs to setup passwordless SSH (hit Enter across all questions!)
- Needs to specify IP addresses for each core on host.
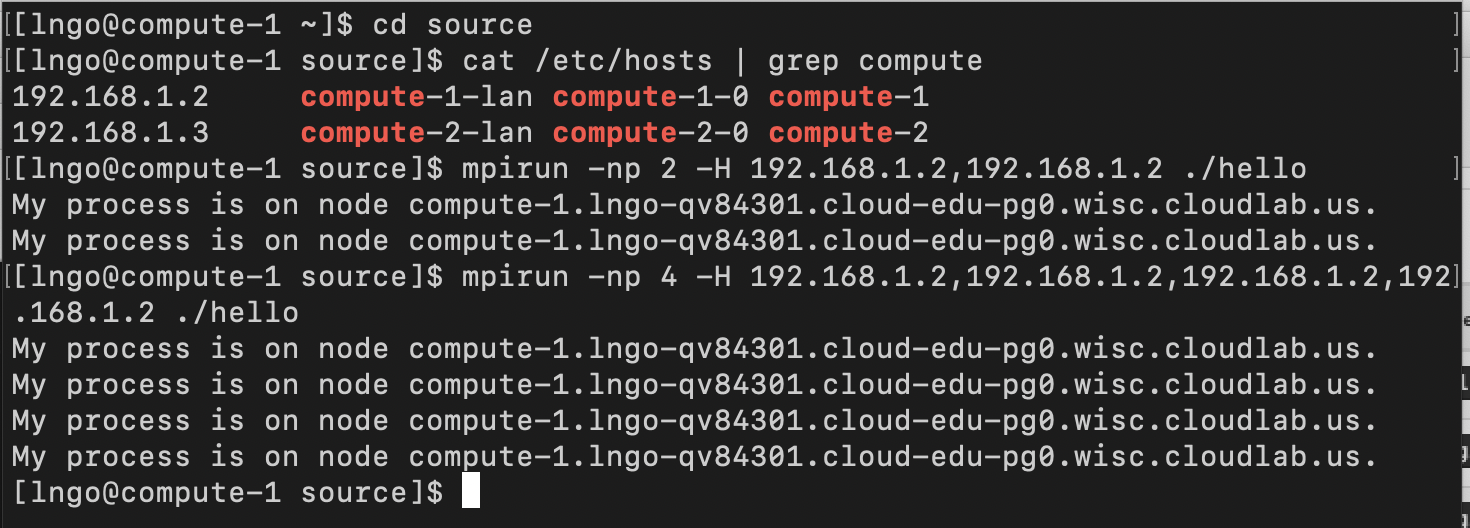
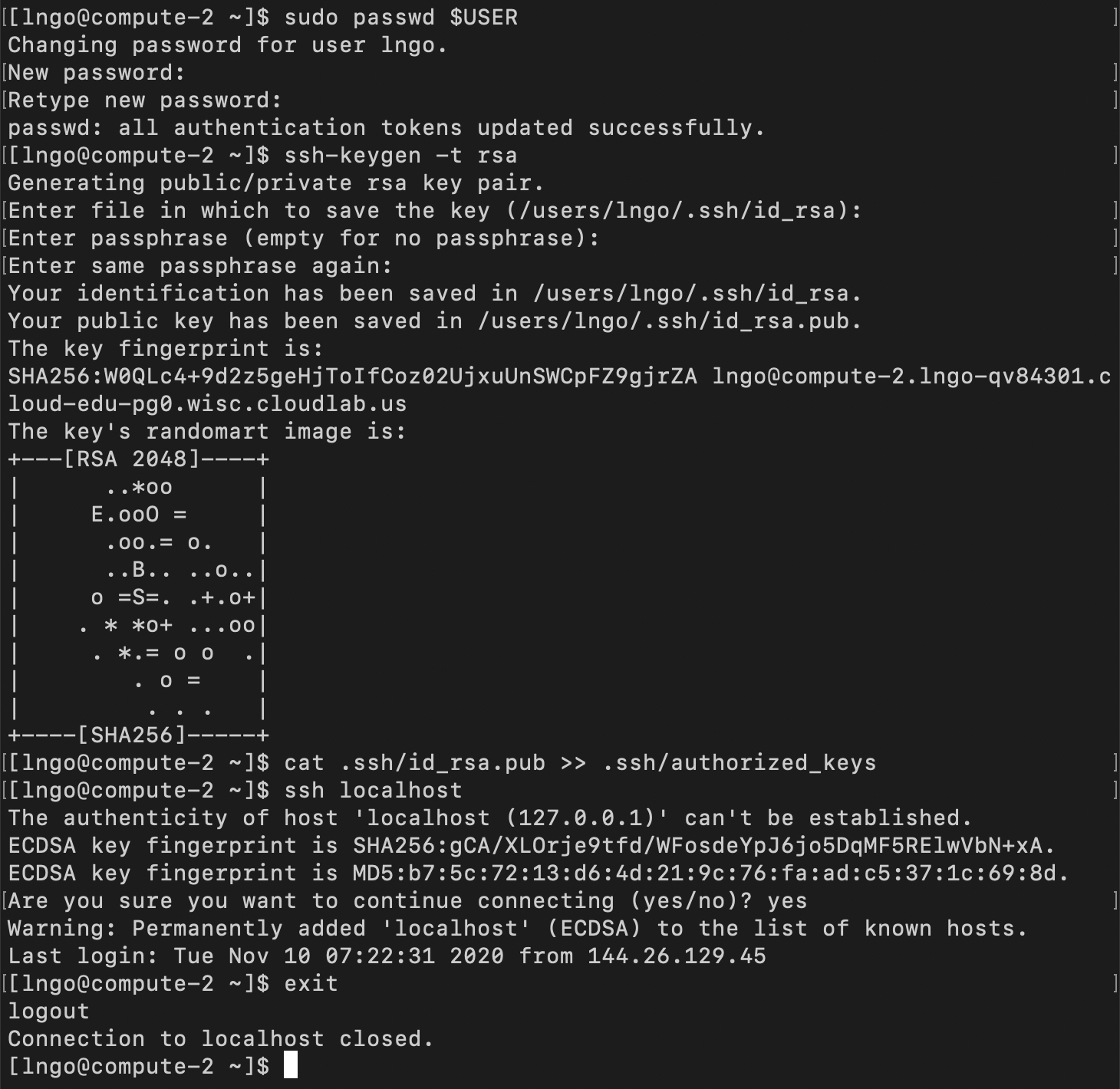
$ cd $ sudo passwd $USER $ ssh-keygen -t rsa $ cat .ssh/id_rsa.pub >> .ssh/authorized_keys $ ssh localhost $ exit $ cd source $ cat /etc/hosts | grep compute $ mpirun -np 2 -H 192.168.1.2,192.168.1.2 ./hello $ mpirun -np 4 -H 192.168.1.2,192.168.1.2,192.168.1.2,192.168.1.2 ./hello
- How can we get this to run across multiple nodes?
- Open a new terminal.
- Log into
compute-2and repeat the above process to create password and passwordless SSH.$ cd $ sudo passwd $USER $ ssh-keygen -t rsa $ cat .ssh/id_rsa.pub >> .ssh/authorized_keys $ ssh localhost $ exit
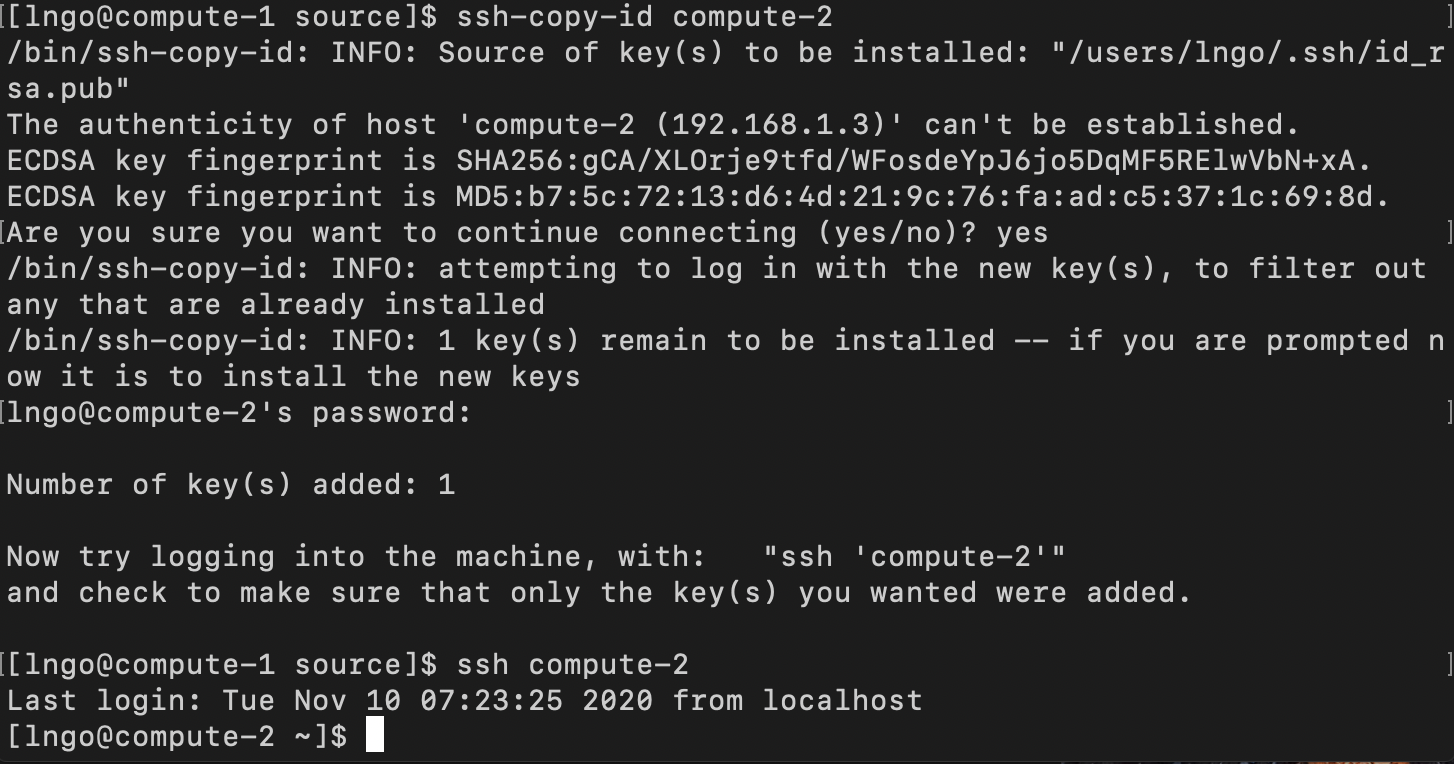
- Copy the key from
compute-1tocompute-2.
- Switch to the terminal that logged onto
compute-1- Answer
yesif asked about the authenticity of host.- Enter the password for your account on
compute-2(that you setup previously!)- If passwordless SSH was successfully setup, a subsequence SSH from
compute-1tocompute-2will not require any password.- Repeat the process to setup passwordless SSH from
compute-2tocompute-1.$ ssh-copy-id compute-2 $ ssh compute-2 $ exit
- On each node,
compute-1andcompute-2, run the followings:$ echo "export PATH=/opt/openmpi/3.1.2/bin/:$PATH" >> ~/.bashrc $ echo "export LD_LIBRARY_PATH=/opt/openmpi/3.1.3/bin/:$LD_LIBRARY_PATH" >> ~/.bashrc
- On
compute-2, repeat the process to copysourceto your home directory and to compilehello.c.- Switch back to the terminal that logged into
compute-1.- View the file
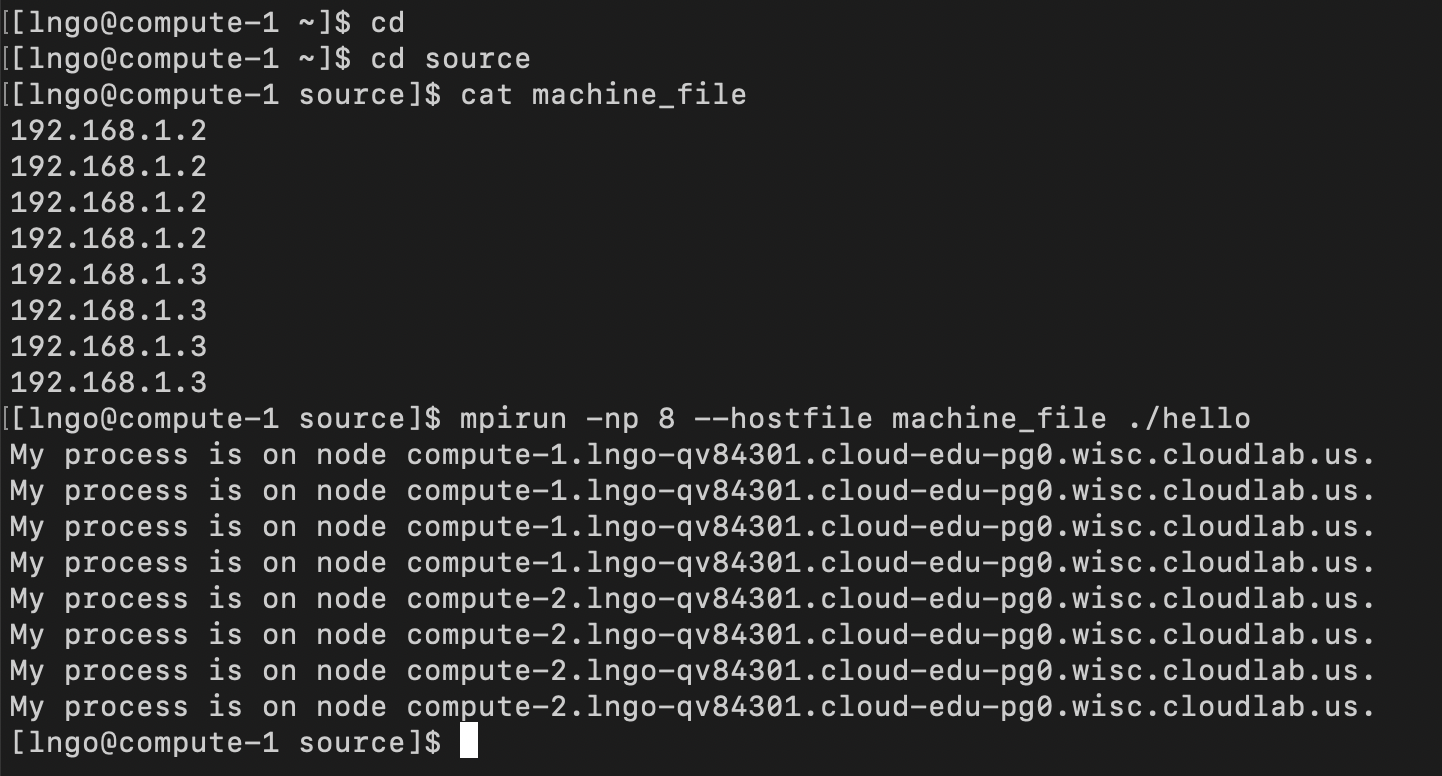
machine_fileinside thesourcedirectory and run the MPI job$ cd $ cd source $ cat machine_file $ mpirun -np 8 --hostfile machine_file ./hello


1. Type of distributed file systems
- Networked File System
- Allows transparent access to files stored on a remote disk.
- Clustered File System
- Allows transparent access to files stored on a large remote set of disks, which could be distributed across multiple computers.
- Parallel File System
- Enables parallel access to files stored on a large remote set of disks, which could be distributed across multiple computers.
2. Networked File System
- Sandberg, R., Goldberg, D., Kleiman, S., Walsh, D., & Lyon, B. (1985, June). “Design and implementation of the Sun network filesystem.” In Proceedings of the Summer USENIX conference (pp. 119-130)
- Design goals
- Machine and operating system independence
- Crash recovery
- Transparent access
- UNIX semantics maintained on client
- Reasonable performance (target 80% as fast as local disk)

3. Networked File System Design
- NFS Protocol
- Remote Procedure Call mechanism
- Stateless protocol
- Transport independence (UDP/IP)
- Server side
- Must commit modifications before return results
- Generation number in
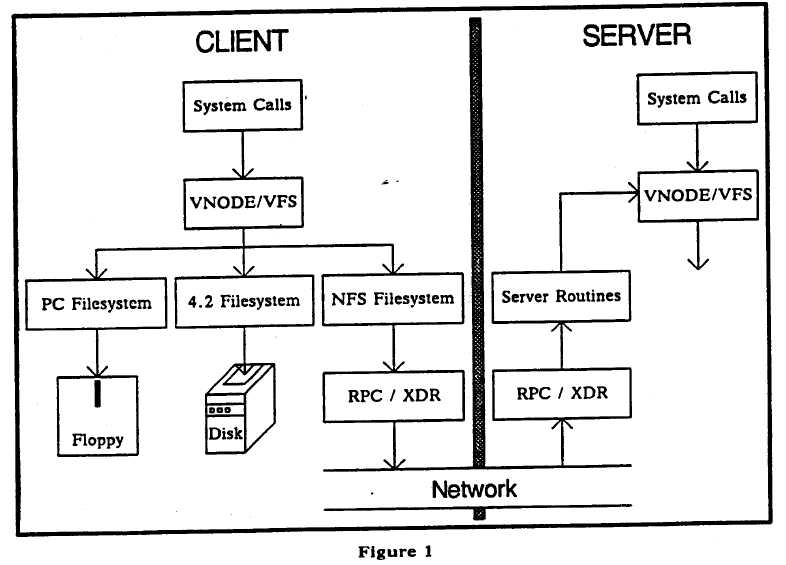
inodeand filesystem id in superblock- Client side
- Additional virtual file system interface in the Linux kernel.
- Attach remote file system via
mount
4. Clustered File Systems
- Additional middleware layers such as the tasks of a file system server can be distributed among a cluster of computers.
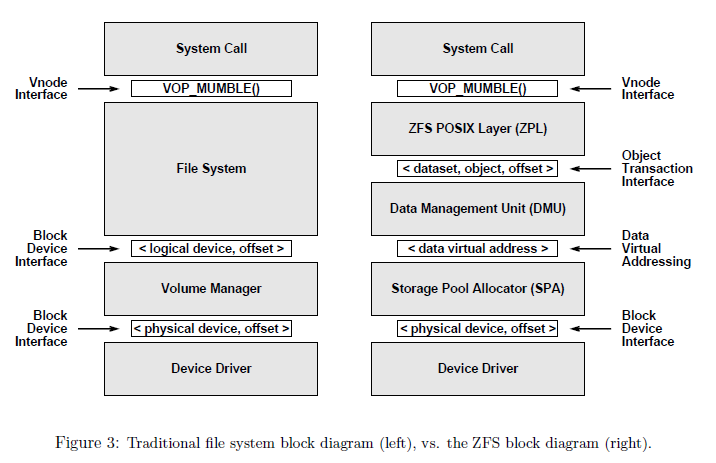
- Example: The Zettabyte File System (ZFS) by Sun Microsystem
- Bonwick, Jeff, Matt Ahrens, Val Henson, Mark Maybee, and Mark Shellenbaum. “The zettabyte file system.” In Proc. of the 2nd Usenix Conference on File and Storage Technologies, vol. 215. 2003.
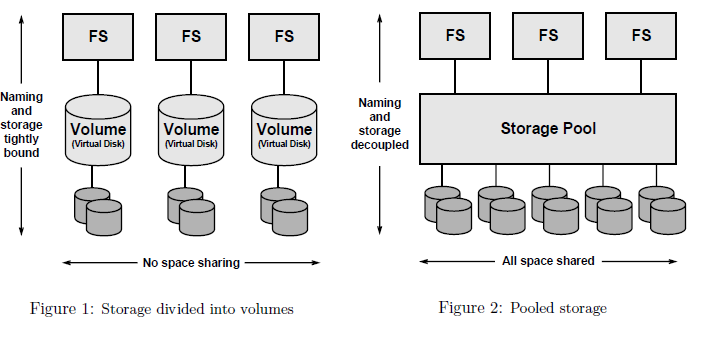
- “One of the most striking design principles in modern file systems is the one-to-one association between a file system and a particular storage device (or portion thereof). Volume managers do virtualize the underlying storage to some degree, but in the end, a file system is still assigned to some particular range of blocks of the logical storage device. This is counterintuitive because a file system is intended to virtualize physical storage, and yet there remains a fixed binding between a logical namespace and a specific device (logical or physical, they both look the same to the user).”
5. Clustered File Systems: design principles
- Simple administration: simplify and automate administration of storage to a much greater degree.
- Pooled storage: decouple file systems from physical storage with allocation being done on the pooled storage side rather than the file system side.
- Dynamic file system size
- Always consistent-disk data.
- Immense capacity (Prediction in 2003: 16 Exabyte datasets to appear in 10.5 years).
- Error detection and correction
- Integration of volume manager
- Excellent performance
6. Parallel File Systems
- Ross, Robert, Philip Carns, and David Metheny. “Parallel file systems.” In Data Engineering, pp. 143-168. Springer, Boston, MA, 2009.
“… The storage hardware selected must provide enough raw throughput for the expected workloads. Typical storage hardware architectures also often provide some redundancy to help in creating a fault tolerant system. Storage software, specifically file systems, must organize this storage hardware into a single logical space, provide efficient mechanisms for accessing that space, and hide common hardware failures from compute elements.
Parallel file systems (PFSes) are a particular class of file systems that are well suited to this role. This chapter will describe a variety of PFS architectures, but the key feature that classifies all of them as parallel file systems is their ability to support true parallel I/O. Parallel I/O in this context means that many compute elements can read from or write to the same files concurrently without significant performance degradation and without data corruption. This is the critical element that differentiates PFSes from more traditional network file systems …”
7. Parallel File Systems: fundamental design concepts
- Single namespace, including files and directories hierarchy.
- Actual data are distributed over storage servers.
- Only large files are split up into contiguous data regions.
- Metadata regarding namespace and data distribution are stored:
- Dedicated metadata servers (PVFS)
- Distributed across storage servers (CephFS)
8. Parallel File Systems: access mechanism
- Shared-file (N-to-1): A single file is created, and all application tasks write to that file (usually to disjoint regions)
- Increased usability: only one file is needed
- Can create lock contention and reduce performance
- File-per-process (N-to-N): Each application task creates a separate file, and writes only to that file.
- Avoids lock contention
- Can create massive amount of small files
- Does not support application restart on different number of tasks
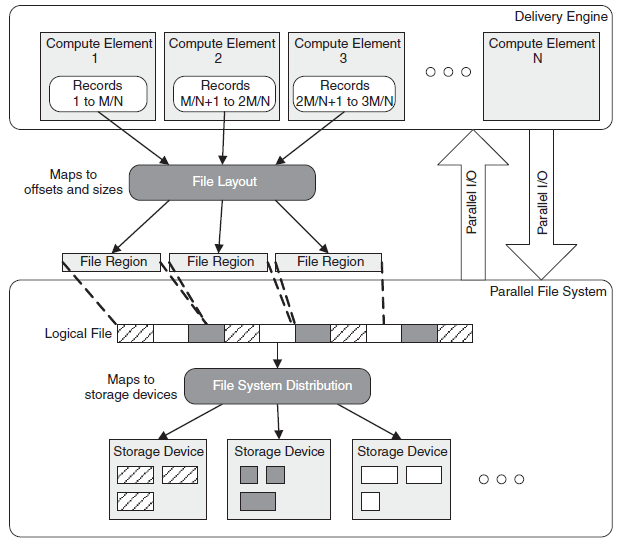
9. Parallel File Systems: data distribution
- Original File: Sequence of Bytes
- Sequence of bytes are converted into sequence of offsets (each offset can cover multiple bytes)
- Offsets are mapped to objects
- not necessarily ordered mapping
- reversible to allow clients to contact specific PFS server for specific data content
- Objects are distributed across PFS servers
- Information about where the objects are is stored at the metadata server
10. Parallel File Systems: object placement
- Round robin is reasonable default solution
- Work consistently on most systems
- Default solutions for: GPFS, Lustre, PVFS
- Potential scalability issue with massive scaling of file servers and file size
- Two dimensional distribution
- Limit number of servers per file
11. Design challenges
- Performance
- How well the file system interfaces with applications
- Consistency Semantics
- Interoperability:
- POSIX/UNIX
- MPI/IO
- Fault Tolerance:
- Amplifies due to PFS’ multiple storage devices and I/O Path
- Management Tools
12. Hands-on: Setup NFS
- Log into CloudLab
- Log into the
headnode on your cluster- Run the following bash commands from your home directory:
$ sudo yum install -y nfs-utils $ sudo mkdir -p /scratch $ sudo chown nobody:nobody /scratch $ sudo chmod 777 /scratch $ sudo systemctl enable rpcbind $ sudo systemctl enable nfs-server $ sudo systemctl enable nfs-lock $ sudo systemctl enable nfs-idmap $ sudo systemctl start rpcbind $ sudo systemctl start nfs-server $ sudo systemctl start nfs-lock $ sudo systemctl start nfs-idmap $ echo "/scratch 192.168.1.2(rw,sync,no_root_squash,no_subtree_check)" | sudo tee -a /etc/exports $ echo "/scratch 192.168.1.3(rw,sync,no_root_squash,no_subtree_check)" | sudo tee -a /etc/exports $ sudo systemctl restart nfs-server
- Log into
compute-1andcompute-2nodes on your cluster- Run the following bash commands from your home directory on both nodes:
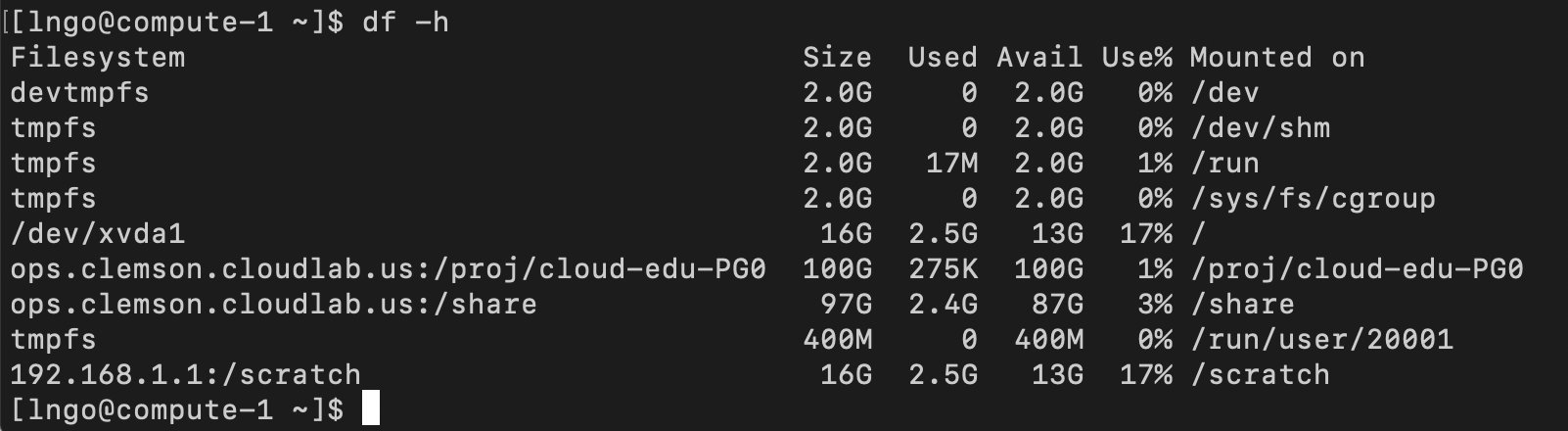
$ echo "export PATH=/opt/openmpi/3.1.2/bin/:$PATH" >> ~/.bashrc $ echo "export LD_LIBRARY_PATH=/opt/openmpi/3.1.2/bin/:$LD_LIBRARY_PATH" >> ~/.bashrc $ sudo yum install -y nfs-utils $ sudo mkdir -p /scratch $ sudo mount -t nfs 192.168.1.1:/scratch /scratch $ df -h
- On
compute-1, run the followings$ cd $ ssh-keygen -t rsa -f .ssh/id_rsa -N '' $ cat .ssh/id_rsa.pub >> .ssh/authorized_keys $ cp -R .ssh /scratch
- On
compute-2, run the following$ cp -R /scratch/.ssh .{: .language-bash}>
- Test passwordless SSH by attempting to SSH to
compute-1fromcompute-2and vice versa.- Log on to
compute-1and run the followings:$ cd /scratch $ cp -R /local/repository/source . $ cd source $ mpicc -o hello hello.c $ mpirun -np 8 --hostfile machine_file ./hello
Key Points