Distributed machine learning with Spark
Contents
Distributed machine learning with Spark#
1. Application: Spam Filtering#
viagra |
learning |
the |
dating |
nigeria |
spam? |
|
|---|---|---|---|---|---|---|
X1 |
1 |
0 |
1 |
0 |
0 |
y1 = 1 |
X2 |
0 |
1 |
1 |
0 |
0 |
Y2 = -1 |
X3 |
0 |
0 |
0 |
0 |
1 |
y3 = 1 |
Instance spaces X1, X2, X3 belong to set X (data points)
Binary or real-valued feature vector X of word occurrences
dfeatures (words and other things, d is approximately 100,000)
Class Y
Spam = 1
Ham = -1
2. Linear models for classification#
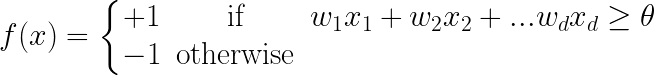
Vector Xj contains real values
The Euclidean norm is
1.Each vector has a label yj
The goal is to find a vector W = (w1, w2, …, wd) with wj is a real number such that:
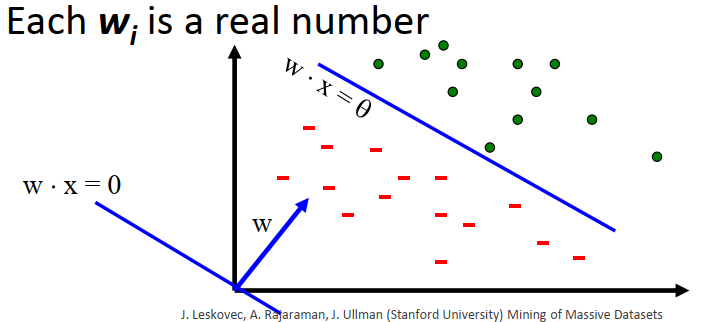
The labeled points are clearly separated by a line:
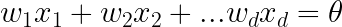 .
.
Dot is spam, minus is ham!
 .
.
3. Linear classifiers#
Each feature
ias a weight wiPrediction is based on the weighted sum:
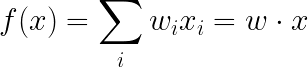
If f(x) is:
Positive: predict +1
Negative: predict -1
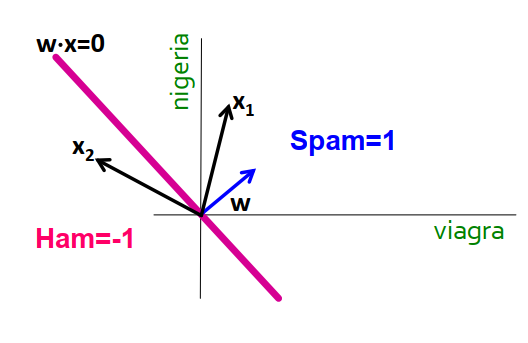 .
.
4. Support Vector Machine#
Originally developed by Vapnik and collaborators as a linear classifier.
Could be modified to support non-linear classification by mapping into high-dimensional spaces.
Problem statement:
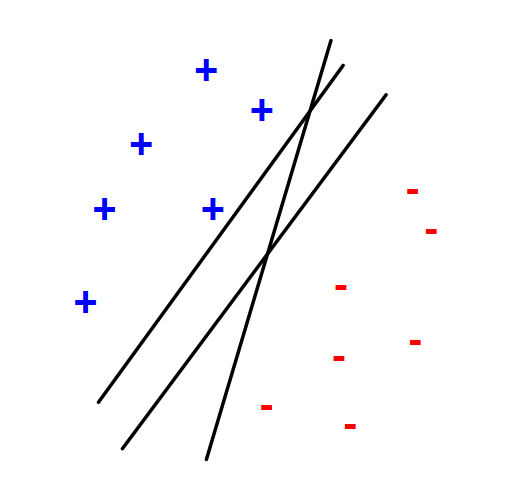
We want to separate
+from-using a line.Training examples:
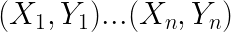 .
.Each example
i: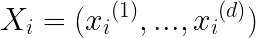 .
.
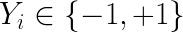 .
.Inner product:
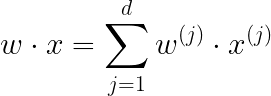 .
.
Which is the best linear separate defined by w?
 .
.
5. Support Vector Machine: largest margin#
Distance from the separating line corresponds to the confidence of the prediction.
For example, we are more sure about the class of
AandBthan ofC.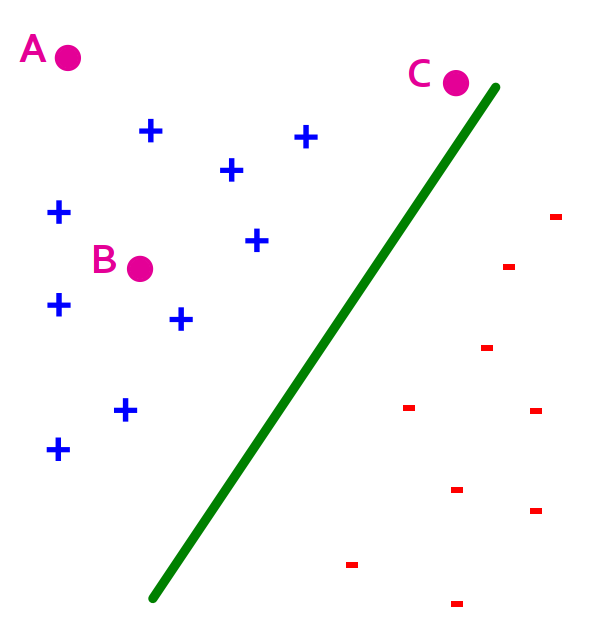 .
.Margin definition:
 .
.
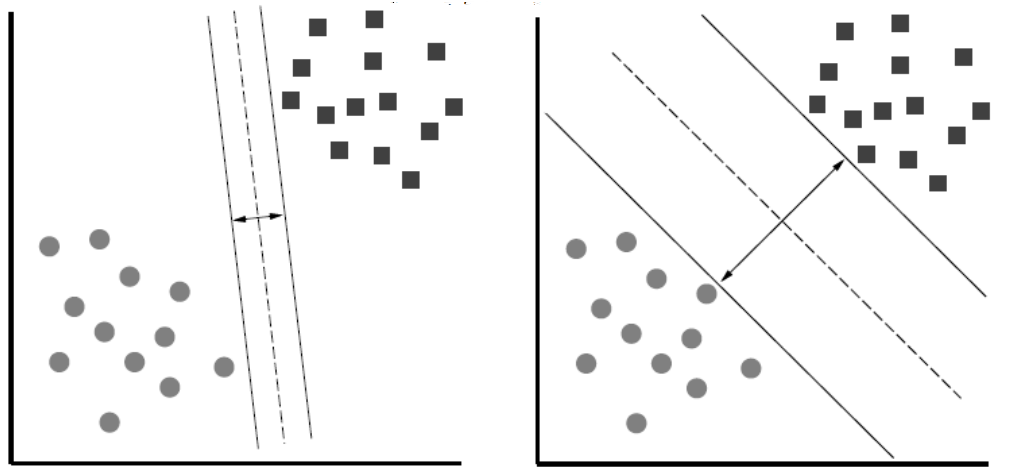 .
.Maximizing the margin while identifying
wis good according to intuition, theory, and practice.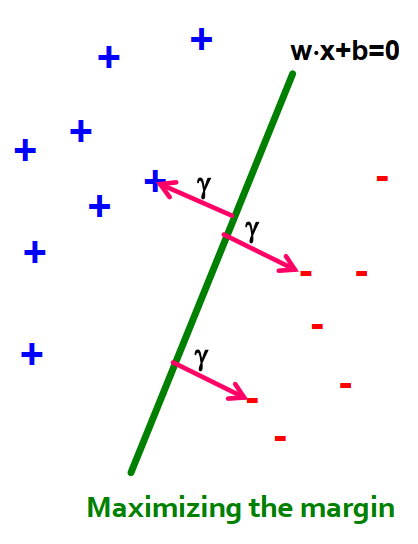 .
.A math question: how do you narrate this equation?
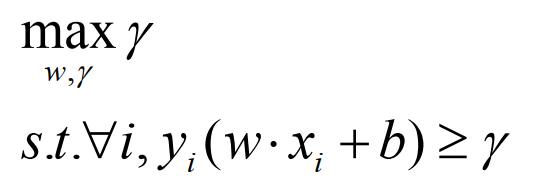 .
.
6. Support Vector Machine: what is the margin?#
Slide from the book
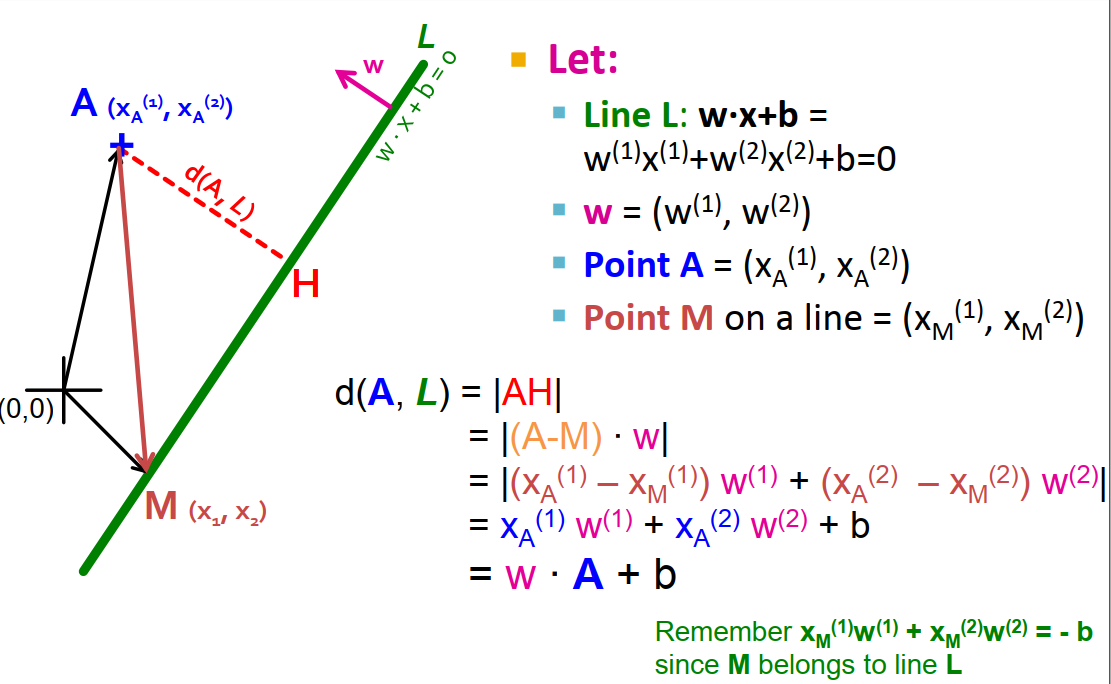 .
.Notation:
Gammais the distance from point A to the linear separator L:d(A,L) = |AH|If we select a random point M on line L, then d(A,L) is the projection of AM onto vector
w.If we assume the normalized Euclidean value of
w,|w|, is equal to one, that bring us to the result in the slide.
In other words, maximizing the margin is directly related to how
wis chosen.For the ith data point:
 .
.
7. Some more math …#
 .
.
After some more mathematical manipulations:
 .
.Everything comes back to an optimization problem on
w: .
.
 .
.
8. SVM: Non-linearly separable data#
 .
.
For each data point:
If margin greater than 1, don’t care.
If margin is less than 1, pay linear penalty.
Introducing slack variables:
 .
.
 .
.
9. Hands-on: SVM#
Download the set of inaugural speeches from https://www.cs.wcupa.edu/lngo/data/bank.csv
Activate the
pysparkconda environment, installpandas, then launch Jupyter notebook
$ conda activate pyspark
$ conda install -y pandas
$ jupyter notebook
Create a new notebook using the
pysparkkernel, then change the notebook’s name tospark-7.Copy the code from
spark-6to setup and launch a Spark application.Documentation:
Question: Can you predict whether a client will subscribe to a term deposit (feature
deposit)?Problems:
What data should the bank data be converted to?
How to handle categorical data?
{% include links.md %}