Frequent Itemsets
Contents
Frequent Itemsets#
1. The market-basket model#
Describe a common form of many-to-many relationship between two kinds of objects.
A large set of
items. e.g.: things sold in a supermarket.A large set of
baskets, each of which is a small set of items. e.g.: things one customer buys on one trip to the supermarket.Number of
basketscannot fit into memory.
2. Definition of a frequent itemsets.#
A set of items that appears in many baskets is said to be
frequent.Assume a value
s: support threshold.If
Iis a set of items.The
supportforIis the number of baskets in whichIis a subset.
Iis frequent if its support issor higher.
3. Example: frequent itemsets#
items = {milk, coke, pepsi, beer, juice}
B1: m,c,b
B2: m,p,j
B3: m,b
B4: c,j
B5: m,p,b
B6: m,c,b,j
B7: c,b,j
B8: b,c
Support value
s= 3 (three baskets)Frequent itemsets:
{m}, {c}, {b}, {j}, {m,b}, {b,c}, {c,j}
4. Applications#
Items: products; Baskets: sets of products.
Given that many people buy beer and diapers together: run a sale on diapers and raise price of beer.
Given that many people buy hotdog and mustards together: run a sale of hotdog and raise price of mustards.
Items = documents; baskets = sentences/phrases.
Items that appear together too often could represent plagiarism.
Items = words, basket = documents.
Unusual words appearing together in large number of documents indicating interesting relationship.
5. Scale of the problem#
Walmart sells hundreds of thousands of items, and has billions of transactions (shopping basket/cart at checkout).
The Web has billions of words and many billions of pages.
6. Association Rules:#
If-thenrules abou the contents of baskets.{i_1, i_2, ..., i_k} -> jmeans: “If a basket contains all of i_1,…,i_k then it islikelyto contain j.”Confidenceof this association rule is the probability of j given {i_1,…,i_k}.The fraction of the basket with {i_1,…,i_k} that also contain j.
Example:
B1: m,c,b
B2: m,p,j
B3: m,b
B4: c,j
B5: m,p,b
B6: m,c,b,j
B7: c,b,j
B8: b,c
An association rule: {m,b} -> c
Basket contains m and b: B1, B3, B5, B6
Basket contains m, b, and c: B1, B6
C = 2 / 4 = 50%
7. Finding association rules#
Find all association rules with support >= s and confidence >=c
Hard part: funding the frequent itemsets.
8. Computation model#
Data is stored in flat files on disk.
Most likely basket-by-basket.
Expand baskets into pairs, triples, etc as you read the baskets.
Use
knested loops to generate all sets of sizek.
I/O cost: per passes (all baskets read).
9. Main-memory bottleneck#
For many frequent-itemset algorithms, main memory is the critical resource.
We need to keep count of things (occurrences of pairs/triples/…) when we read baskets.
The number of different things we can count is limited by main memory.
Swapping counts is going to be horrible.
10. Naive algorithm#
Hardest problem is finding
frequent pairsbecause they are the most common.Read file once, counting in main memory the occurences of each pair.
For each basket of
nitems, there will ben(n-1)/2pairs, generated by double-nested loops.If
n^2exceeds main memory, we fails.
11. Naive algorithm: how do we count.#
Count all pairs using a triangular matrix.
Requires 4 bytes per pair for all possible pairs: 2n^2
Keep a table ot triples [i, j, c] with c is the count of pair {i,j}.
Requires 12 bytes only for pairs with count > 0: 12p with p is the number of pairs that actually occur.
12. A-Priori algorithm.#
Limit the need for main memory.
Key idea:
monotonicityIf a set of items appears at least
stimes, so does every subset of this set.
Contrapositive: If an item
idoes not appear insbaskets, then no pair containingican appear in s baskets.A-Priori algorithm:
Pass 1: read baskets and count the item occurrences. Only keep items that appear at least
stimes -frequent items.Pass 2: read baskets again and only count in main memory only those pairs whose both items were found to be frequent from Pass 1.
Repeat the process with increasing number of items added to only sets found to be
frequent.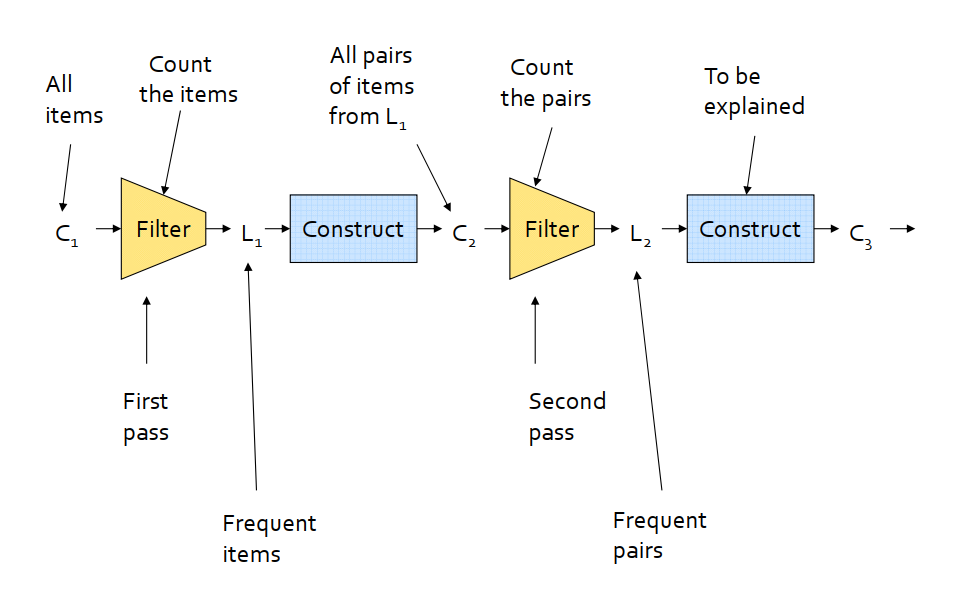
C1 = all items
In general, L_k are members of C_k with support greater than or equal to
s.C_(k+1) includes (k+1) sets, each k of which is in L_k.
13. A-Priori at scale#
Under two passes.
SON: Savasere-Omiecinski-Navathe
Adaptable to a distributed data model (mapreduce).
Repeatedly read small subsets of the baskets into main memory and perform
a-priorion these subsets, using a support that is equal to the main support divided by the total numbers of subsets.Aggregate all candidate itemsets and determine which are frequent in the entire set.
14. Hands-on: SON on Spark#
Download the small movie dataset
15. Hands-on: Processing XML data#
Download the NSF Awards Data between 2011 and 2021.
Review the XML Schema
What is an interesting question?
{% include links.md %}